Credit Risk Scoring & Loan Default Prediction
End-to-end ML pipeline predicting loan defaults with SHAP explainability and 0.788 AUC.
View on GitHubCase Study
How it was built
Problem
Lenders need credit models that are both predictive and auditable. Regulators require an explanation for every adverse decision, which rules out black-box ensembles unless you can attach feature-level reasoning to each score. The German Credit dataset adds a realistic twist: defaults are the minority class, so naive models just predict 'pay back' for everyone.
Approach
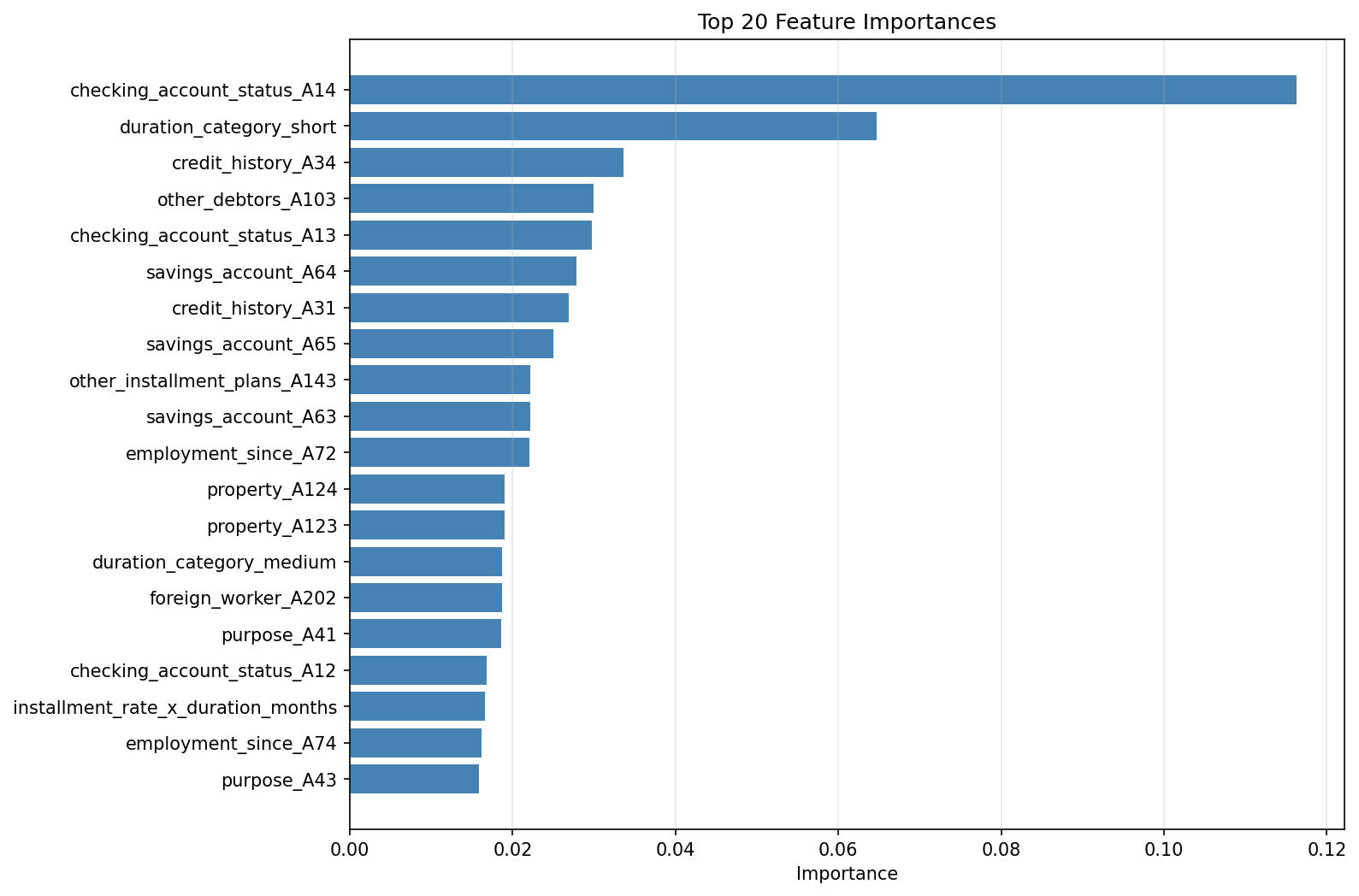
Trained three classifiers — Logistic Regression, Random Forest, and XGBoost — under cross-validated hyperparameter tuning. Engineered 20 raw features into 67 via interactions and polynomial terms, applied SMOTE to the training fold only (never the holdout), and attached SHAP explanations to the winning model for per-prediction attribution.
Try it live
Key Decision
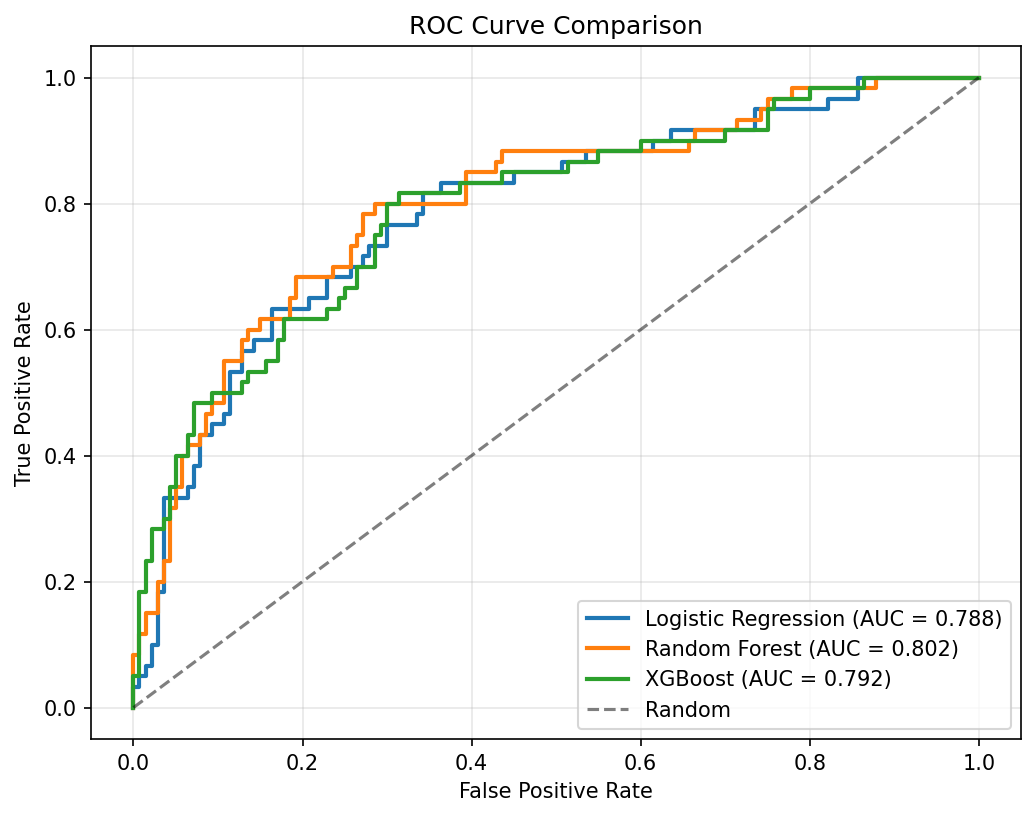
Picked Logistic Regression over the tree ensembles even though XGBoost is the default reach in credit work. On this dataset size the logistic generalized best (0.788 AUC vs. lower out-of-sample for the trees), and the regulatory story is far cleaner: every coefficient is a one-line explanation, and SHAP values reduce to signed feature contributions a credit officer can read.
Result
0.788 AUC on the holdout set with full SHAP attribution, deployed as a CLI for batch scoring. The interactive widget on this page runs the same logistic structure live so you can see how each feature pushes the default probability.
Results
Key metrics
0.788
Best AUC Score
67
Engineered Features
3
Models Compared
SMOTE
Class Imbalance Method
Approach
Technical overview
Dataset & Preprocessing
The German Credit Dataset presents a realistic class imbalance — a common challenge in credit scoring. SMOTE (Synthetic Minority Oversampling Technique) was applied to the training set to ensure the model learned meaningful default patterns rather than simply predicting the majority class.
Feature Engineering
Raw features were expanded from 20 to 67 through interaction terms, polynomial features, and domain-driven transformations. This expansion gave tree-based models additional signal while the logistic regression benefited from the interaction terms directly.
Model Comparison
Three classifiers were trained and evaluated — Logistic Regression, Random Forest, and XGBoost — each with cross-validated hyperparameter tuning. Logistic Regression achieved the best generalization at 0.788 AUC, outperforming the more complex tree ensembles on this dataset size.
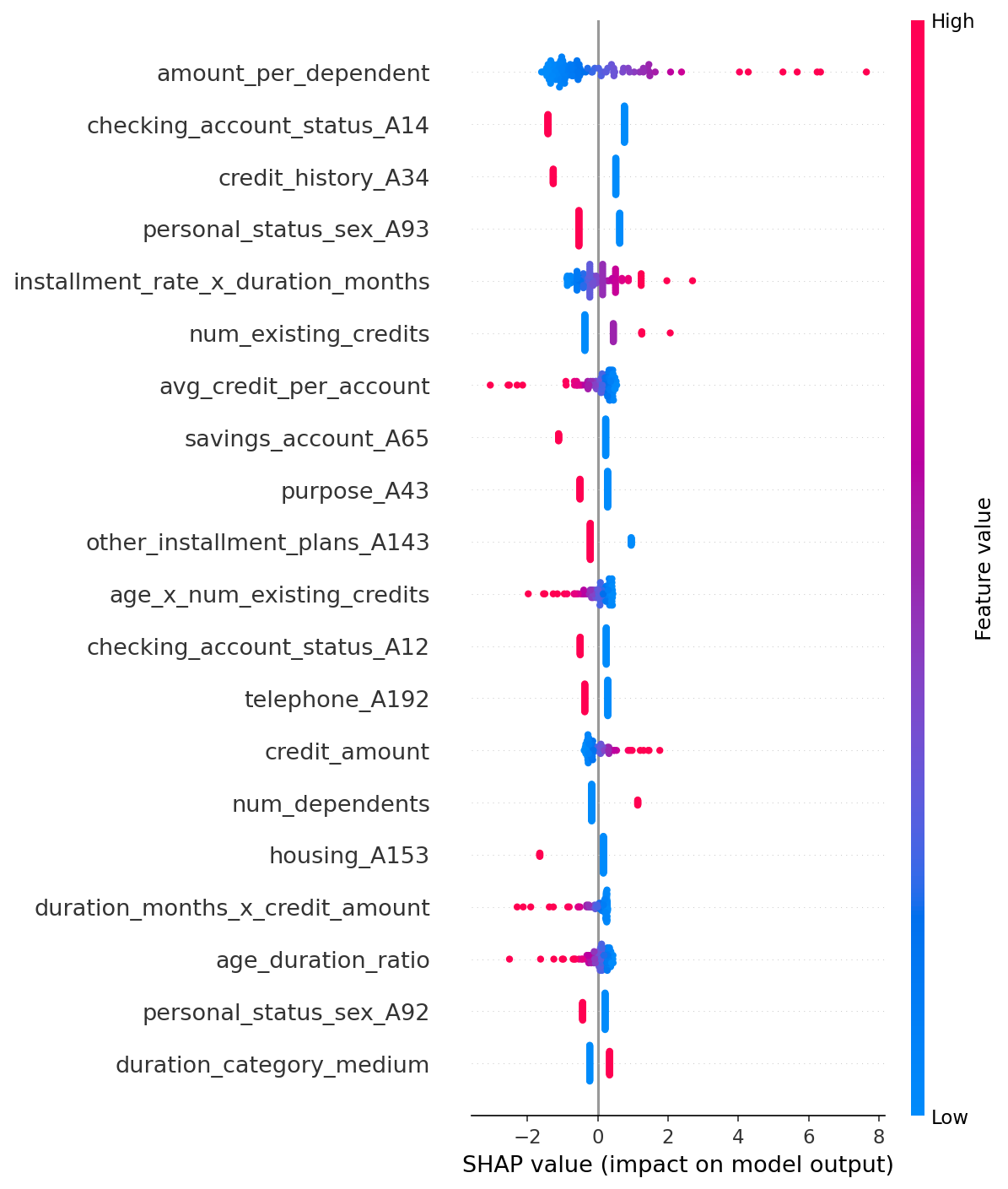
Explainability with SHAP
SHAP (SHapley Additive exPlanations) values were computed for the best model to produce both global feature importance rankings and individual prediction explanations. In credit risk contexts, model interpretability is not optional — regulators require lenders to justify adverse decisions. SHAP provides that audit trail.
Gallery
Output & visualizations
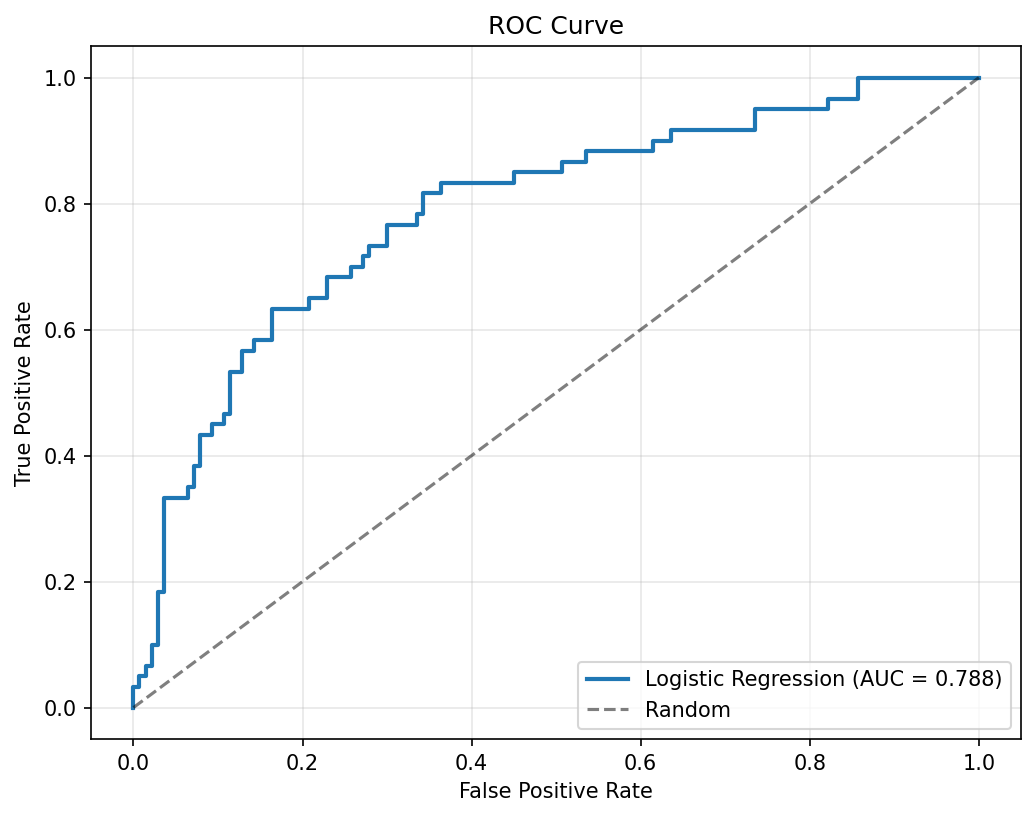
ROC Curves — Logistic Regression vs. Random Forest vs. XGBoost
SHAP Summary Plot — Global feature importance across all predictions
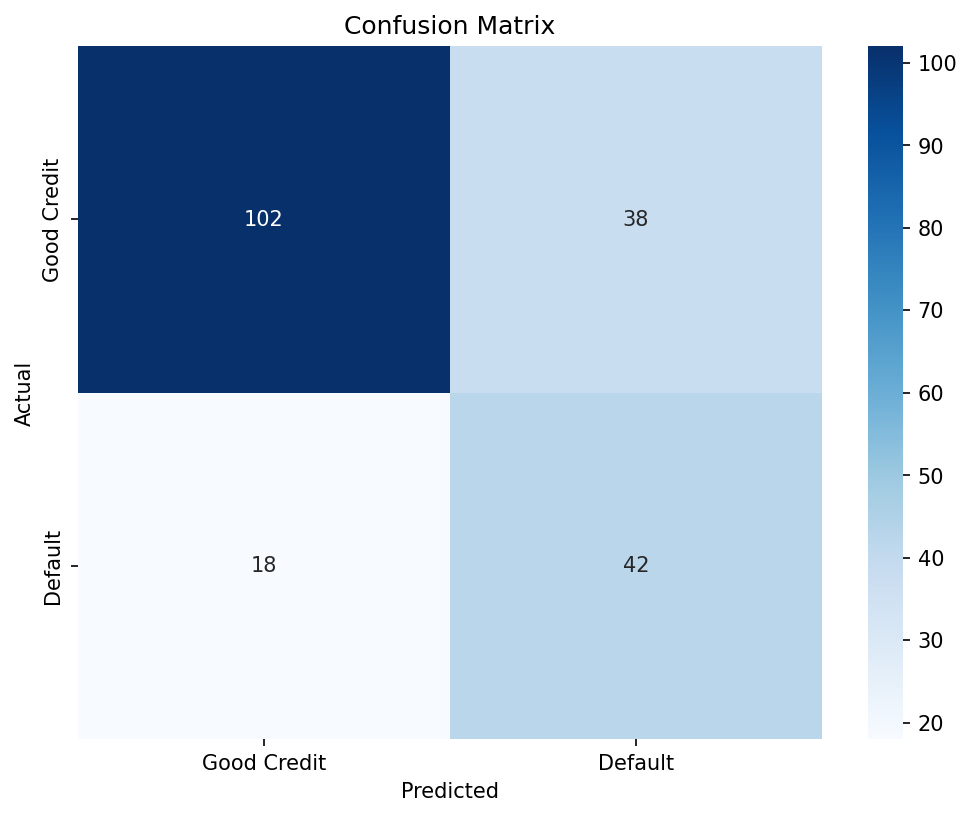
Confusion Matrix — Best model classification results on holdout set
Model Comparison — AUC and F1 across all three classifiers
Feature Importance — Top features driving default predictions
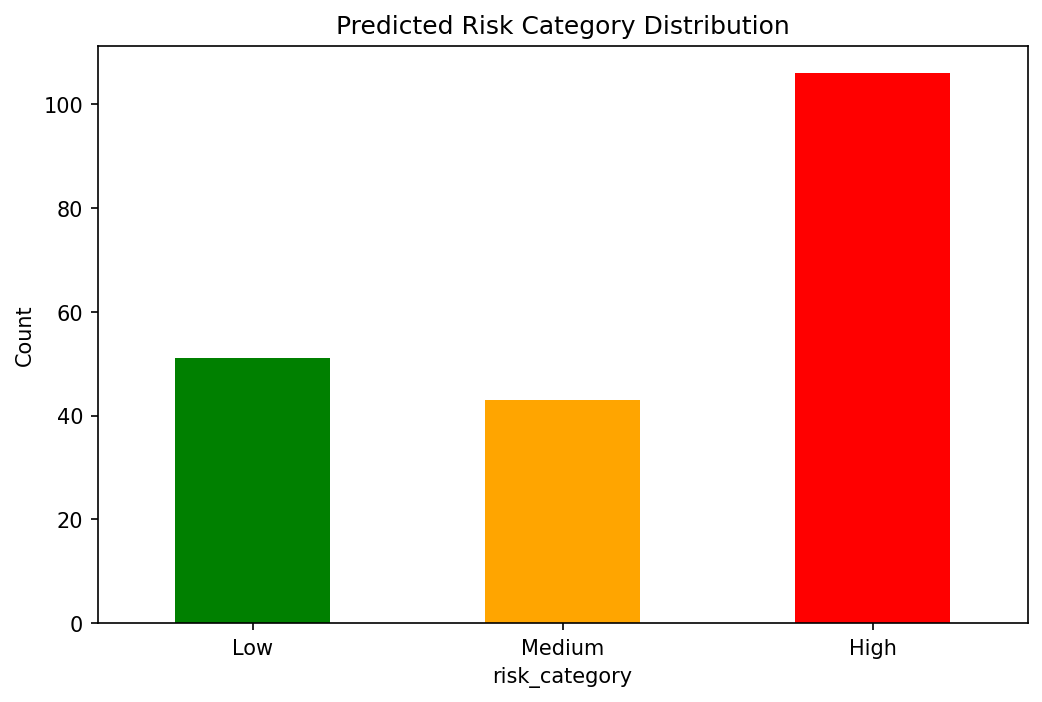
Risk Distribution — Predicted probability distribution by outcome
Stack