LDA Topic Modeling Algorithm
Latent Dirichlet Allocation implemented from scratch via Gibbs Sampling with perplexity-optimized hyperparameter search.
View on GitHubResults
Key Metrics
Scratch
Implementation Depth
Gibbs
Sampling Method
Perplexity
Optimization Metric
PDF + CSV
Input Formats Supported
Approach
Technical Overview
Mathematical Foundation
LDA models each document as a mixture of latent topics, and each topic as a distribution over vocabulary. The generative process assumes documents are produced by sampling topics from a Dirichlet prior, then sampling words from those topic distributions. Implementing this from scratch required deriving the full posterior update equations.
Gibbs Sampling
Collapsed Gibbs Sampling was used for posterior inference — iteratively resampling the topic assignment for each word token given all other assignments. This is the standard approach for LDA when an exact solution is intractable, and implementing it directly demonstrates command of Bayesian inference mechanics.
NLP Preprocessing Pipeline
A full preprocessing pipeline handles tokenization, stopword removal, lemmatization, and minimum frequency filtering before fitting. Both PDF documents (via pdfplumber) and CSV corpora are supported as inputs, making the tool applicable to a broad range of document analysis tasks.
Hyperparameter Search
The Dirichlet concentration parameters α and β, along with the number of topics K, were tuned via grid search scored by perplexity on a held-out document set. Lower perplexity indicates better generalization — the model is less surprised by unseen documents under its learned topic structure.
Gallery
Output & Visualizations
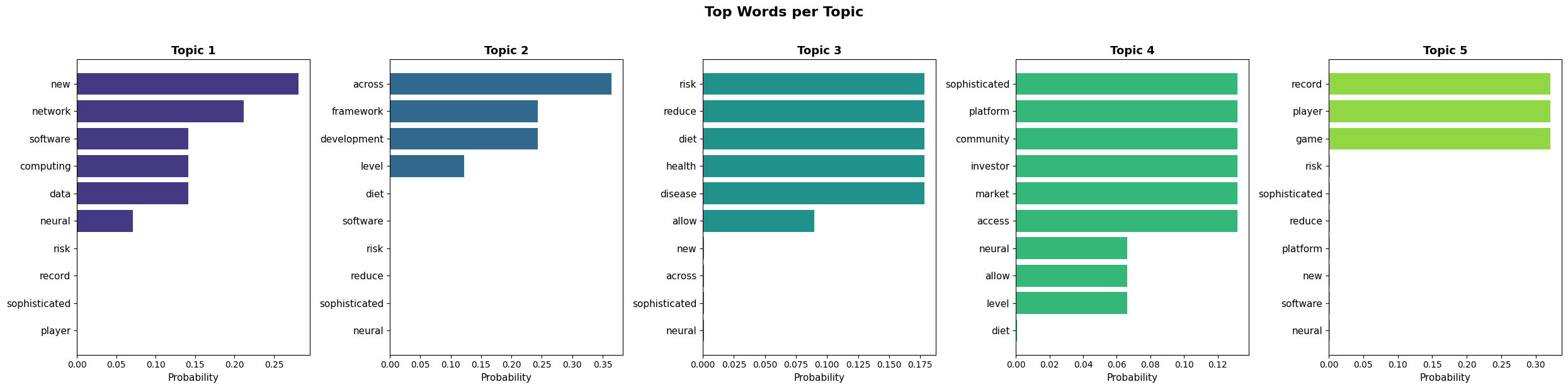
Topic-Word Distributions — Top 10 words per discovered topic
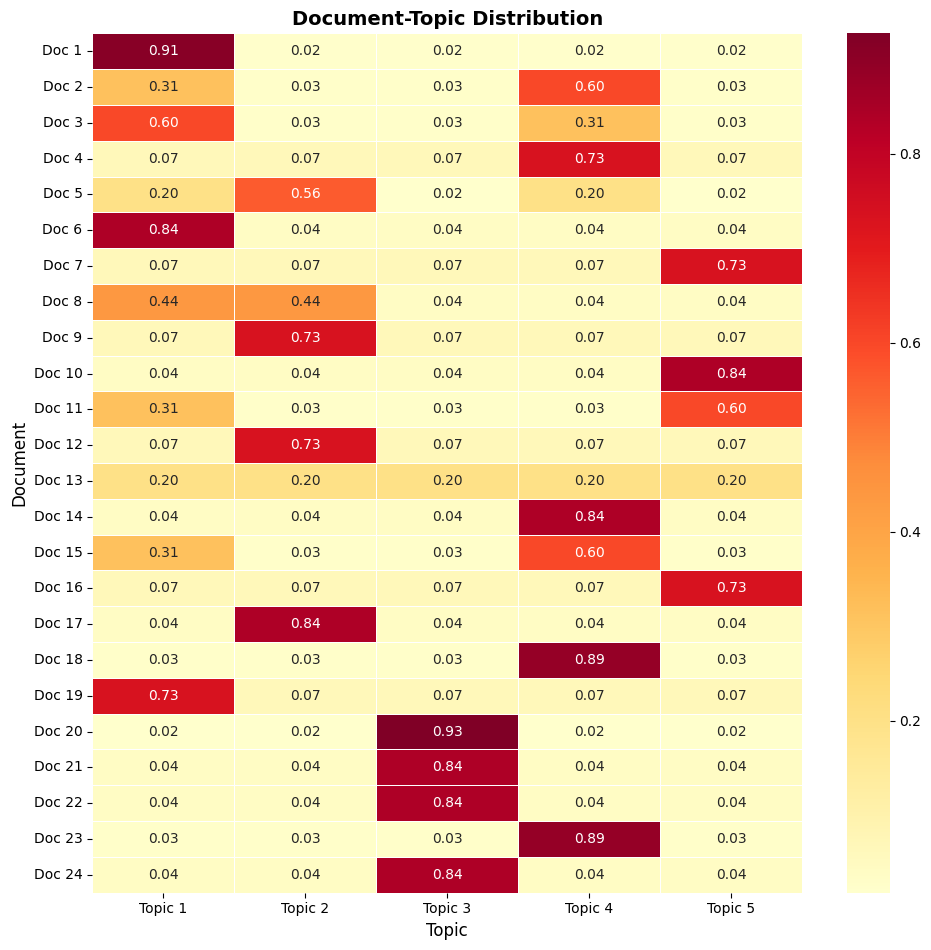
Document-Topic Matrix — Topic mixture proportions across the corpus
Stack